오토인코더의 종류는 다양하다. Single Auto Encoder, Deep Auto Encoder, Stacker Auto Encoder, Denoising Auto Encoder. 그리고 경우에 따라서는 Auto Encoder를 합칠 수도 있고 이러한 어플리케이션을 Google에서 볼 수 있다.
여기에서는 각각의 단일 경우에 대해서만 그림과 간단한 설명으로 살펴 보도록 한다.
Auto Encoder
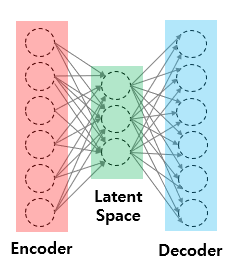
: Encoder와 Decoder - 즉, 입력과 출력이 대칭이 되도록 네트워크를 디자인 한 오토인코더
Stacked Auto Encoder
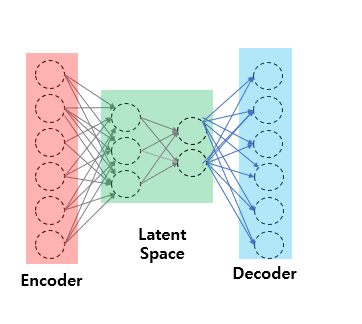
: Latent space역시 단층이 아니라 여러 층이 될 수 있다. 이에 따라 이러한 네트워크를 Stacked layer라고 이름을 붙였다. 이러한 네트워크는 일반적으로 Single Auto Encoder보다 좋은 성능을 보인다. (Deep learning이 layer가 깊어 질 수록 성능이 좋아지는 것 처럼)
Deep Auto Encoder
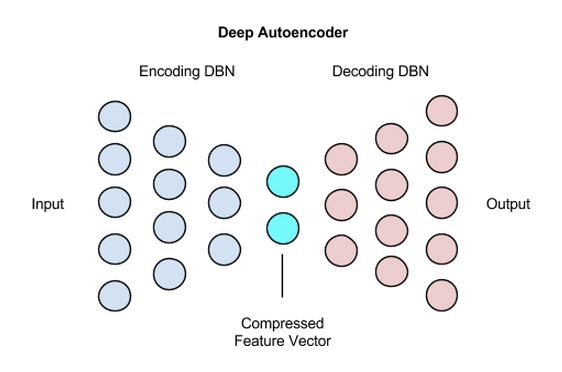
더 이상 그리기가 힘들어서 캡쳐로 대체한다. (https://wiki.pathmind.com/deep-autoencoder)
딥 오토안코더는 네트워크를 최소 4개 사용해야 한다. 그리고 Encoder와 Decoder를 대칭으로 사용해야 함.
Denoising Auto Encoder
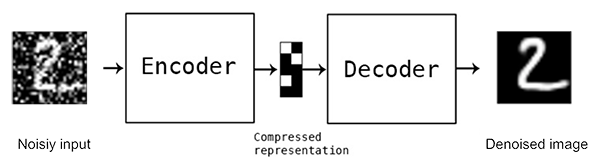
그림이 별로 없다. 설명을 많이 보충해야 할 것 같다.
- 일단 상기의 그림을 보면 Encoder쪽 그림이 깨끗하지 못하다. 즉. Noise가 섞여 있다. Network에 Keras에서는 Gaussian잡음을 넣는 것는 코드를 지원하는 것으로 기억한다.
- 그리고 가우시안 Noise를 넣은 다음에는 Encoder에 잡음이 섞인 Input'를 넣은 다음 압축(Copressed represenation)을 한다.
- 그리고 Decoder는 해당 Compressed representation을 어떻게든 깨끗하게 처음처럼 Gaussian Noise가 섞이지 않은 처음 Input(주의!....Input'가 아님) 으로 복원하는 것을 목표로 한다.
Sparse Encoder도 있는데 이건 시간나면 해 보겠다. 지금은..잘 모른다. =_ㅠ
끝
'머신러닝 > 딥러닝 - 오토인코더' 카테고리의 다른 글
| RNN의 개념 (0) | 2021.12.29 |
|---|---|
| 오토인토더란(3) - Deep Auto Encoder With MNIST DATA (0) | 2021.11.09 |
| Auto Encoder란(2) - Denoising Auto Encoder/Stacked Auto Encoder (0) | 2021.11.05 |
| Auto Encoder란(1) (0) | 2021.11.04 |
| Keras로 딥러닝 만들고 파라미터 튜닝하기(Grid Search (0) | 2021.01.26 |