앞으로 실습할 모든것인 Shape, Slicing,[텐서의 조작], Tensor, Vector, 텐서의 핵심 속성 그리고 간단한 그래디언트 기반 최적화를 설명하는 장이다. 따라서 엄밀히 말하면 Numpy에 포스팅해야 하지만 케라스 책에 있으므로 여기에 포스팅한다.
2.1 2장의 도입부 및 MNIST로 인한 전반적인 설명
2.2 신경망을 위한 데이터 표현
신경망은 Tensor라고 불리우는 다차원 넘파이 배열에 데이터를 저장하는 것으로부터 시작된다. 텐서에는 다음과 같은 데이터 형이 존재한다.
2.2.1 스칼라(0D텐서)
하나의 숫자만 담고 있는 텐서이다. 거의 사용하지 않음.
2.2.2 벡터(1D텐서)
하나의 축(행/열 등)을 가진 것을 벡터라고 부름.
2.2.3 행렬 또는 Matrix(2D 텐서)
2개의 축(행/열)을 가지고 있는 데이터 숫자가 채워진 사각 격자임.
2.2.4 3D텐서 이상
3D텐서는 사진 [R,G,B]를 나타내지만 그 이상인 4D, 5D는 Video를 나타낼 때 사용하는데 우리 눈으로 관찰하기는 불가능하다. 2.2.1 ~ 2.2.4를 각각 넘파이로 표현하여서 나타내보면 다음과 같다.

먼저 0D 의 경우 이를 Numpy 배열로 생성하여 보면 하나의 값만 들어 있는 것을 알 수 있음. 또한 축이 몇 개 존재하는 지 알아 보기 위해서 ndim command를 실시 해본 결과 0으로 존재하지 않는 것을 알 수 있음.

1차원 배열의 경우는 다음과 같이 우리가 일반적으로 알고 있는 리스트 형태의 벡터가 만들어지고 축이 하나 존재함을 알 수 있음. 그리고 해당 벡터는 5개의 원소를 가지고 있으므로 5차원 벡터라고 함. 단, 이것은 축이 아니고 5D tensor도 아님을 명심해야 함. [5D Tensor는 Tensor가 5겹으로 놓이는 것임.]

가장 많이 쓰이는 matrix 인 2차원 텐서임. 백터와 달리 축이 하나 더 있어서, 데이터를 더 다양하게 표현 할 수 있음을 알 수 있음.

마지막으로 3차원 Tensor를 표현해 보면 행, 열이 몇 개 쌓여 있는 지 표현하는 값인 z축이 붙었음을 알 수 있음. 나중에 MNIST의 응용과 함께 자세히 알아 볼 것임. 여기까지를 정리해서 신경망의 데이터를 표현하는 Tensor의 핵심속성을 알아보면 다음과 같음.
2.2.5 핵심속성
축의 개수 : 행/열/깊이 : ndim 명령어로 알아 볼 수 있음.
크기(Shape): 텐서의 각 축을 따라 얼마나 많은 차원이 있는지를 나타내는 것. 앞에 나온 2D에서 Shape는 (3,5) - 3행 5열
3D는 (3, 3,5) - 3쌓여 있음 [3행 5열]
이를 구체적으로 확인 해 보기 위해서 MNIST의 dataset을 load히고 확인해 본다.
따라서 data를 로드하고 train_image에 대해서 ndim과 shape를 확인해 보면


축의 개수는 3개인데, 28 행 28열이 60000곂 쌓여 있음을 알 수 있다. [여기서는 이미지이므로 28 by 28 pixel이 60000개 있음] 이를 matplotlib으로 확인해 보면

실제로 이미지를 출력해 볼 수 있고, 형태 또한 이전 우리가 예측했던 것과 같음을 알 수 있다.
지금까지 신경망에 축적되는 데이터의 핵심속성에 대해서 알아 보았고 어떻게 출력해 보는 지 알아 보았다. 기본적으로 데이터를 알더라도 데이터를 적재한 다음에는 무조건 shape나 ndim은 확인해 보는 것이 좋다. 추후에 학습할 때 에러가 날 소지가 다분하기 때문이다.
2.2.6 넘파이로 텐서 조작하기
이전에는 특정 이미지, 즉, 4번째 이미지 train_images[4]를 선택했다. 하지만 더 많은 이미지를 한 번에 선택해보거나 특정 범위로 이미지를 선택하고 싶을 때가 있다. 즉, slicing하고 싶을 때가 있다. 이렇게 특정 원소들을 선택 하는 것을 Slicing이라고 하는 데 다음 연산을 보자. 먼저 다음예는 11 번쟤부터 101번째까지의 값만 60000개 중에서 Slice하여 새로운 값을 my_slice에 저장한다.

:(콜론)이 전체 인덱스를 의미하므로 여기서는 28을 뜻함. [28*28]
10~100 이므로 60000개중에서 11~100의 90개를 선택한다.
주의 할 것은 위의 주석 부분과 같이 :은 생략 가능하다! (하지만 일관되게 써주는 것이 나중에 보는데 편함.)
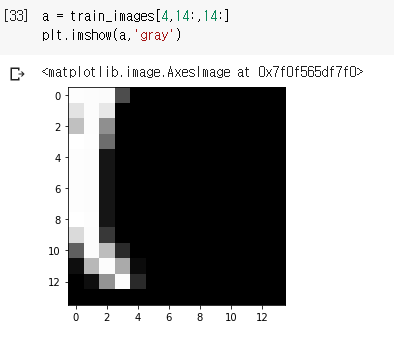
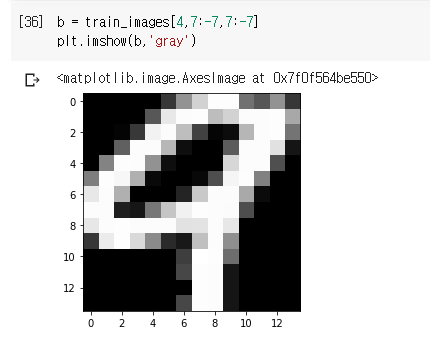
각 배열의 축(행/열)을 따라 어떠한 인덱스 또는 인덱스 사이도 선택 할 수 있으므로 위와 같이 설정하면 픽셀 에 따른 값을 표현하는 것이 가능하다.
2.2.7 배치 데이터
일반적으로 사람들이 머신러닝을 하면서 그냥 넘어가는(나의 경우 그랬음) 부분이다. 여기서 짚고넘어가면 좋을 듯 하다. 배치데이터란 딥러닝의 용어로서 일반적으로 딥러닝을 할 때 한 번 반복[Epoch: 이것도 딥러닝 용어임]할 때 모든 데이터를 사용하지 않고 데이터의 일부분만 사용한다. 예를 들어 MNIST 에서는 전체 60000개 중에 128개의 배치를 사용한다고 하면 다음과 같다.
1st: batch = train_images[:128] / 2nd: batch = train_images[128:256] ... nth: batch = train_images[128*n:128*(n+1)]
2.2.8 텐서의 실제 사례
데이터의 종류는 다음과 같다.
벡터 데이터(sampe, features)
시계열 데이터(나중에 추가)
이미지(sample, height, width, channels)
동영상(samples, frames,height,width,channels)
2.2.9 벡터 데이터
사진이나 동영상 이외의 일반적으로 다루는 대부분의 데이터. 위에서 보다시피 Feature와 Sample축으로 이루어져 있다.

2.2.10 시계열 데이터
주식 또는 트윗 셋. 나중에 추가
2.2.11 이미지 데이터
이미지 데이터는 앞엑서 봤던 MNIST와 같이 [height, width, color_channel]의 3차원으로 이루어짐. MNIST의 경우 흑백 이미지이므로 컬러 채널이 1이고 컬러 채널은 보통 RGB인 경우 세개이므로 3이다.
예를 들어 256*256의 RGB이미지 128개의 배치는 (128,256,256,3)크기의 텐서에 저장 될 수 있음.
- 이미지 데이터 공부하면서 좀 더 Update
2.2.12 비디오 데이터
5D Tensor가 필요한 경우임. 하나의 비디오는 프레임의 연속이고, 각 프레임은 컬러 이미지로 표현 됨. 따라서
프레임의 연속은 [frames, height, width, color_channel] 4D 텐서 로 표현되고
비디오의 배치는 [samples, frames, height, width, color_channel] 5D로 표현됨.
예) 60초짜리 144*256유튜브 비디오 클립을 초당 4프레임으로 샘플링하면
frames > 240 / samples>4 / height > 144 / width > 256 / color_channel >3
(4, 240, 144, 256, 3).크기의 텐서에 저장
이제 2장도 1/3정도 봤습니다. 다음에는 2.3장과 2.4장을 살펴 볼 건데 브로드캐스팅과 텐서의 형태, 그리고 경사하강법의 간단한 이론 정도에 대해서 나오는 것 같습니다. 자세히는 안 봐서 모르겠습니다. 어려운 문제는 없는 것 같으니 함께 포스팅 하는 것으로 하겠습니다.
'머신러닝 > 딥러닝 - 오토인코더' 카테고리의 다른 글
| tensorflow model 못 읽는 문제 해결 (0) | 2020.12.08 |
|---|---|
| key error: mean_absolute_error (0) | 2020.02.09 |
| 3. 신경망의 시작하기(3.1 신경망의 구조) (0) | 2020.02.06 |
| #2시작하기 전에: 신경망의 구성요소(2.3 신경망의 톱니바퀴: 텐서연산) (0) | 2020.02.03 |
| Keras 시작 With [케라스 창시자에게 배우는 딥러닝] (0) | 2020.02.02 |