. : 이 시스템에서 스크립트를 실행할 수 없으므로 C:\Users\USER\Documents\WindowsPowerShell\profile.ps1 파일을 로드할 수 없습니다. 자세한 내용은 about_Execution_Policies(https://go.microsoft .com/fwlink/?LinkID=135170)를 참조하십시오.
> 파워쉘에서의 권한 에러
Step 1. 파워쉘 관리자 권한으로 실행
Step2. get-executionPolicy
: 현재 권한 상태 확인, Restricted이면 로컬에서 스크립트를 실행할 수 없는 상태 인 것. 따라서 VS Code에서 에러가 발생
Step3. 권한을 상승 시켜 줘야 함
: Set-ExecutionPolicy RemoteSigned
, 권한을 상승 시키면 문제가 발생할 수 있다 어쩌구저쩌구 하는데 별 문제 없을 것이므로 Y
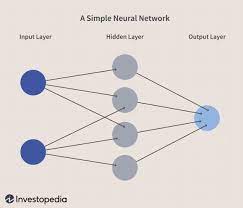
- Input값이 Hidden layer에서 선형 함수를 거친 다음 Activation Function(tanh)를 거치고 Output으로 바로 전환디는 과정을 거침.
NN
- 그러나 RNN은 Hidden layer에서 선형함수를 거친 다음Activation Function(tanh)가 바로 Output으로 전달되지 않고, 다시 Input 값으로서 전달 됨. 그 다음 다시 해당 값이 선형 함수를 거치고 Actication Function을 거친 다음 다음 Input 값으로 전달 됨. (반복) => Recurrent Neural Network => 순서가 있는 데이터를 처리하는데 강점을 가짐.
RNN
- 순서가 있는 데이터?
: 내부 요소들이 동일하다고 하더라도 순서가 바뀌면 통합적으로 완전히 다른 의미가 되는 것.
예) 텍스트 데이터.
I work at google(나는 구글에 근무한다)
I google at work(나는 회사에서 구글링한다)
: 내부 요소는 동일하지만 순서가 바뀌니까 다른 의미가 되었다.
그렇다면 우리가 RNN으로 잘 알고 있는 주식 데이터를 살펴보자. (종가만)
1일 2일 3일 4일
1000 1050 900 1060
1일 3일 2일 4일
1000 900 1050 1060
- 내부 요소는 같지만 내가 의도하는 바는 전혀 다르다. 나는 시계열로 일별 종가를 필요로 하였는데 전혀 다른 값이 왔다. 이런 데이터는 RNN으로 손쉽게 처리 할 수 있다.
- RNN은 순서가 있는 데이터를 온전히 파악하기 위하여 은닉측 내에 순환적 구조(Recurrent structure)를 이용하여 과거의 데이터를 기억(Remember)해 두고 있다가 새롭게 입력으로 주어지는 데이터와 은닉층에서 기억하고 있는 과거 데이터를 연결 - (New Input+Recurrent Output)시켜서 그 의미를 알아내는 기능을 수행.
=> 데이터 분석 결과가 데이터 분석 결과에 영향을 미칠 경우 RNN을 사용하자!
[RNN의 동작 원리]
가장 간단한 텍스트 데이터(I work at google)를 분석하면서 동작 원리를 알아 보자.
1. 먼저 문장을 각 요소별로 분리한다. (데이터 전처리 = 형태소 분리)
: I/work/at/google
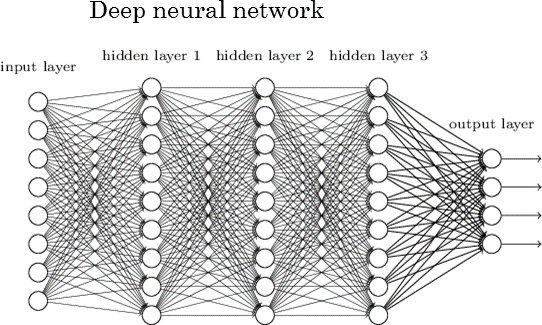
2. 신경망 구조 설계
: 입력 - 은닉 - 출력
: 은닉층으로는 tanh를 사용한다. 그리고 최종 분류로는 softmax를 사용한다.
: 출력층은 명사, 대명사, 동사, 전치사 4가지 Class를 분류한다.
3. 먼저 I가 입력층으로 들어감. I는 선형회귀를 서친 다음 tanh를 거침. 이전에 아무 값도 들어오지 않았으므로 I를 그대로 분석함. 이후 출력층에서는 다시 한 번 선형회귀를 거치고 softmax를 통해서 해당 단어(I)가 어떤 class에 속하는 지 분류해 냄. 여기서는 대명사.
4. 다음으로 Work를 입력.
같은 신경망에 Work가 들어감. 기본에 I가 잔존해 있어서 이 값이 영향을 줌. 하지만 분류는 위 3의 과정과 같이 똑같이 해낼 수 있음. 즉, 동사로 분류.
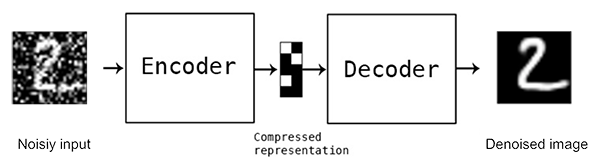
오토인코더의 종류는 다양하다. Single Auto Encoder, Deep Auto Encoder, Stacker Auto Encoder, Denoising Auto Encoder. 그리고 경우에 따라서는 Auto Encoder를 합칠 수도 있고 이러한 어플리케이션을 Google에서 볼 수 있다.
여기에서는 각각의 단일 경우에 대해서만 그림과 간단한 설명으로 살펴 보도록 한다.
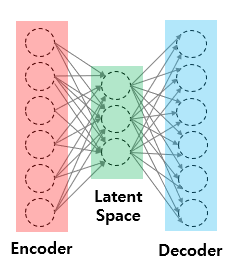
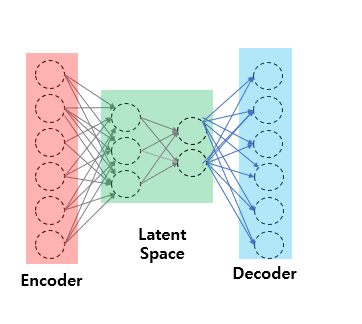
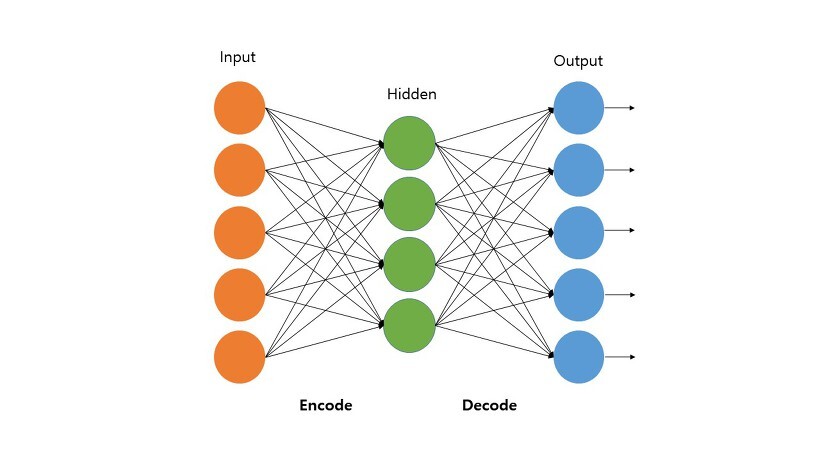
Auto Encoder
: Encoder와 Decoder - 즉, 입력과 출력이 대칭이 되도록 네트워크를 디자인 한 오토인코더
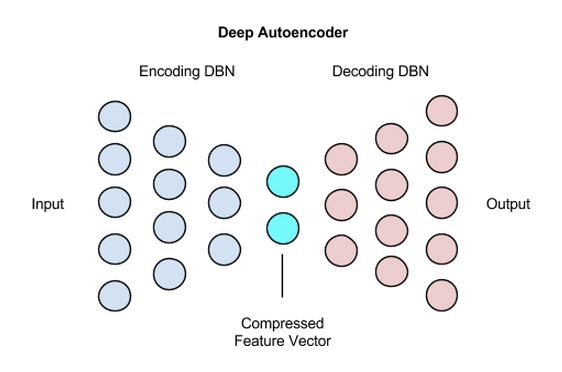
Stacked Auto Encoder
: Latent space역시 단층이 아니라 여러 층이 될 수 있다. 이에 따라 이러한 네트워크를 Stacked layer라고 이름을 붙였다. 이러한 네트워크는 일반적으로 Single Auto Encoder보다 좋은 성능을 보인다. (Deep learning이 layer가 깊어 질 수록 성능이 좋아지는 것 처럼)
Auto Encoder자체가 비지도 학습이지만 Stacked Encoder는 Latent Space를 더 많이 사용하여 레이블되지 않은 데이터가 많을 때 사용하는 방법이다. 즉, Hidden layer를 더 많이 사용함으로써, 1) 전체 데이터를 학습시켜서 데이터를 레이블링한 다음 2) 하위 레이어를 사용하여 다시 학습시키는 방법을 사용하여 성능을 증가 시키는 방법을 사용한다.
이 방법으로 일반적인 오토인코더보다 성능이 훨씬 개선되지만 정확한 수식이나 코드는 아직 보지 못했다. 최근에는 Denoising과 Stacked Auto Encoder를 섞어서 사용하는 것 같은데 이러한 방법에 대해서도 알아 봐야 할 것 같다. 다음에는 이, Stacked Denoising Auto Encoder아니면 Stacked나 Denoising Autoencoder의 코드를 알아 보도록 하겠다.